Models of Learning
Bayesian Learning
Developed by
Jill O'Reilly
Hanneke den Ouden
-August 2015
Fitting real data using a grid search
Finally, we can start to plot the data we collected from real subjects!
Individual data: you!
First, let's estimate the learning model for your own data.subjects = *your subject number*;
simulate = false;
fitData = true;
plotIndividual = true;
... save, and run. If you didn't do the task, just pick subjects 1:2.
This will show you 3 types of plots:
- Trial-wise plot that you saw earlier plotting your own choices and the true underlying probability of reward for the blue slot-machine (p(reward|blue)), the running-average choices (dashed red line), and now in turquoise the estimated probability of choosing blue (p(choose blue).
Does the estimated choice probability follow your choices reasonably well?- Likelihood surface plot. Is the surface plot nicely peaked? Or is there a lot of structure in the plot that might indicate a correlation between parameter values?
- Marginal parameter distributions. Are the distributions relatively normal, or very skewed? Are they peaked (ie do you have high confidence in a single value) or very broad . Are the distributions cut off at the bounds? That might indicate you need to relax the bounds a little.
Group data
We'll next do the analysis across all the data. First, let's have a look at what the group data actually looks like, when averaged across our subjects. In RLtutorial_main set :subjects = 'all';
simulate = false;
fitData = false;
plotIndividual = false;
... save, and run
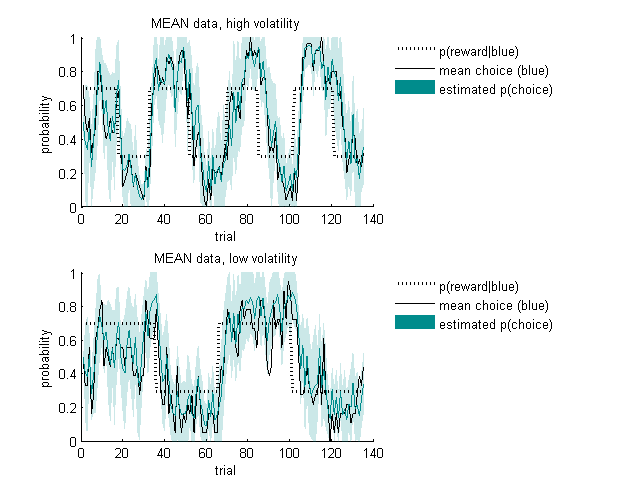
This plot does shows you the observed average choice across participants for each trial (which is why there are no error bars!).
You also get a bar plot with the average proportion of correct choices for both the high and low volatile groups
- Does it look like one of the two groups is better than the other?
- How does this compare to the simulated data? Can you think of why these might differ?
Next we will fit the model to all of the available data. Set,fitData = true;
... save. This time, instead of pressing 'run', type in the command line:
fitted = RLtutorial_main
... and hit Enter. This will return the fitted parameter values to the workspace.
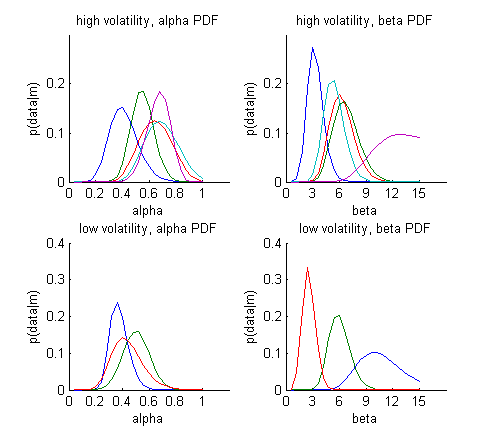
First, we'll look at the figure, showing full probability distributions for each of the parameters for each subject. Below you see an example with only a few of the subjects.
?When looking at the full plot of all of the subjects, do you think that the parameter estimates are very different for the high and low volatility groups? Or perhaps you find these plots a little hard to read?
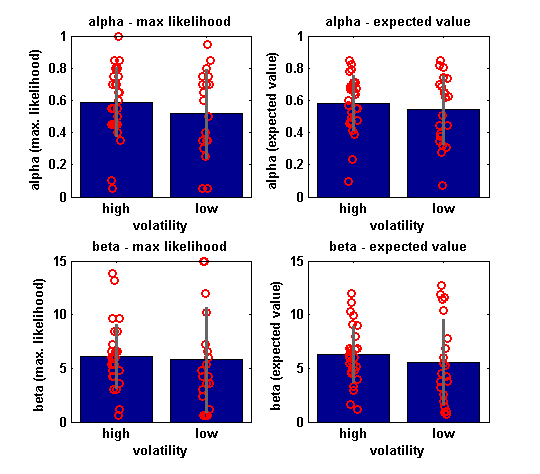
Indeed, because these parameter density plots are a little hard to read, we can also summarise these parameter estimates (based on the maximum likelihood and expected value) across subjects:?Do you notice any marked differences between the EV and ML estimates?
?Finally, let's have a look at how the average choice probability compares to the average choices
?